Working with JSON
Lesson 6: Handling large UTF-8 strings
- In the previous lessons in this series, strings have been used to represent JSON in memory as a text format.
- Strings in DataFlex have limitations; their length is limited by the maximum argument size, and it’s OEM data (not Unicode data).
- It is common to use UTF-8 as the encoding type when JSON is used over the web. The JSON parser internally stores data as UTF-8.
- Two APIs, ParseUtf8 and StringifyUtf8, have been added to allow larger pieces of JSON to be collected in the UTF-8 format. They return Uchar arrays, which support larger strings in DataFlex.

- Set_Field_Value, Get_Field_Value, Field_Current_UCAValue, Read_Block, and Write_Block are functions that support the UChar array.ConvertUCharArray of cChartTranslate can be used to translate it into different formats such as a variant string or a regular string.

DEMONSTRATION - This sample shows how to use ParseUtf8 and StringifyUtf8
- The file used for this sample is called LargeJsonSample and contains source code and a file containing JSON called CustomerData.json. The large JSON file contains an array of customers and their order information.
- This lesson will show how to parse the data into structs and then how to do something with it after its parsed.
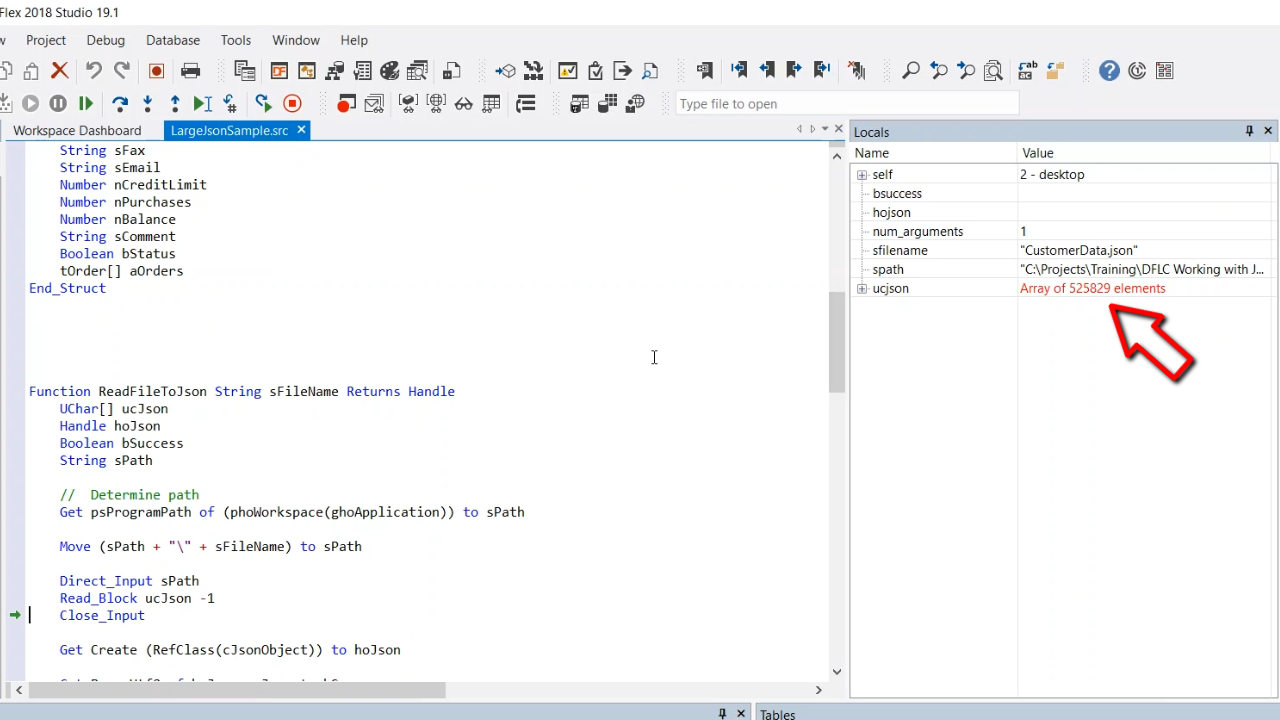
- The ReadFileToJson function will pass a file name that returns a handle to the JSON object. Then a UChar array is created to house the JSON data. The path is assembled then Read_Block is called to read the entire file to memory. The value for ucJson is shown as having 525,829 elements. It is not recommended to expand it to view.
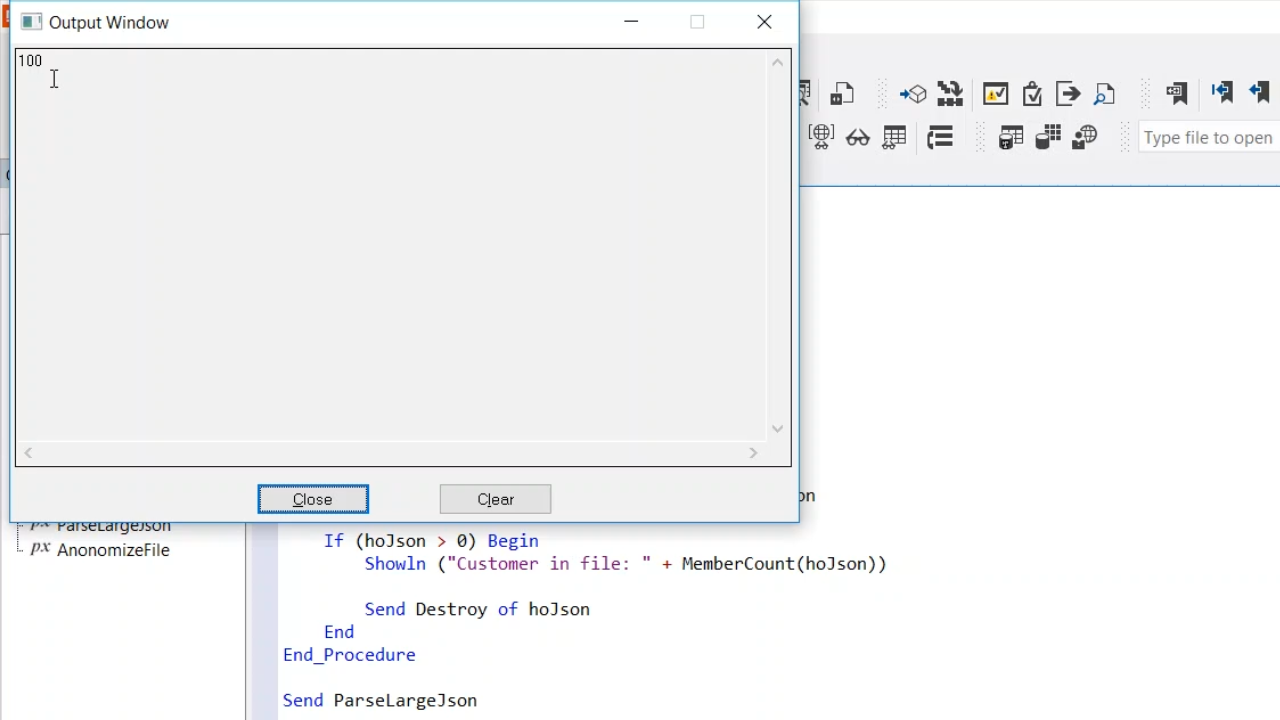
- The file is then closed, a JSON object is created in memory and ParseUtf8 is called. ParseUtf8 functions as ParseString, but instead of a string being parsed it’s a UChar array. If successful, it will return the handle to the JSON object. The number of customers in the file will be counted calling MemberCount on hoJson. hoJson is then destroyed.
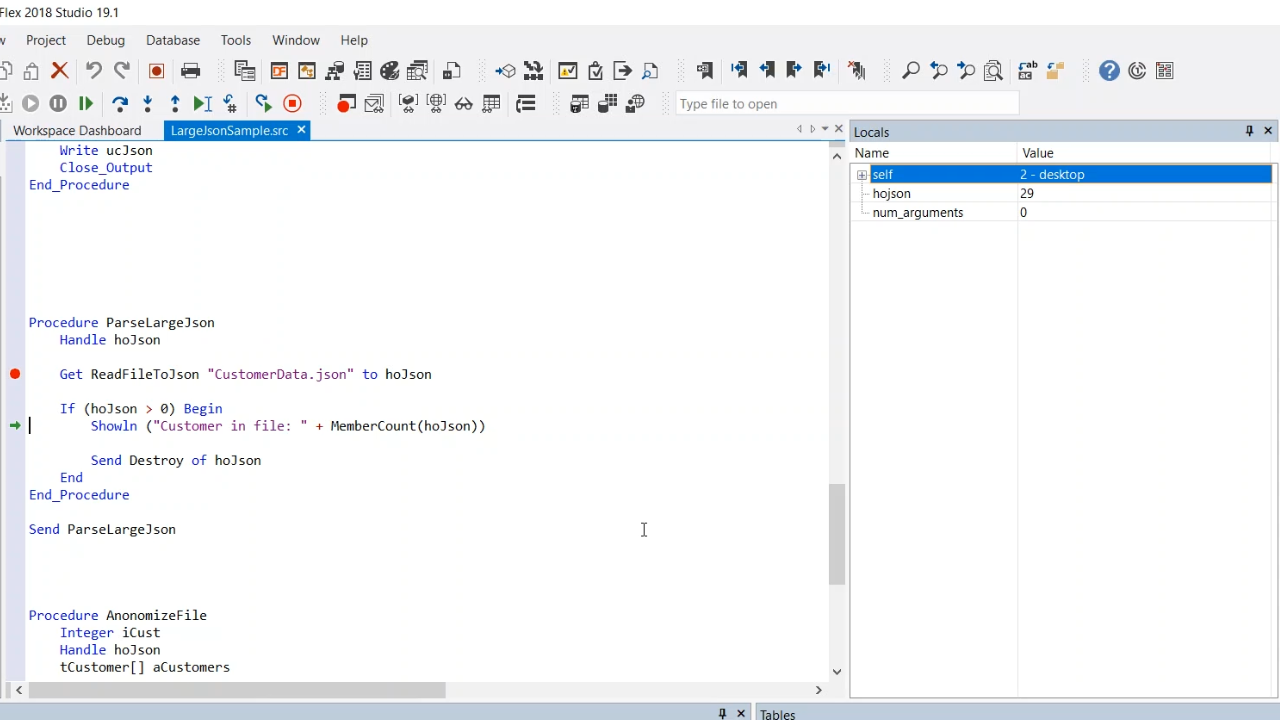
- Running the procedure shows that there are 100 customers in the file.
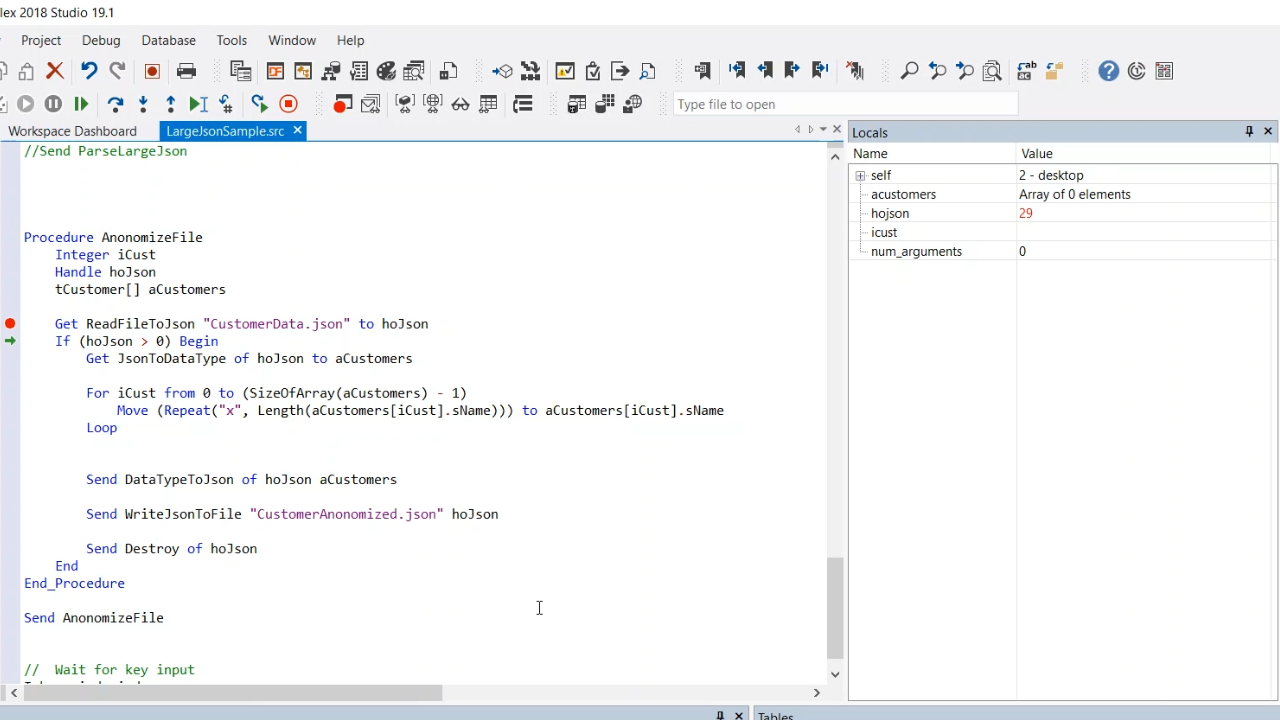
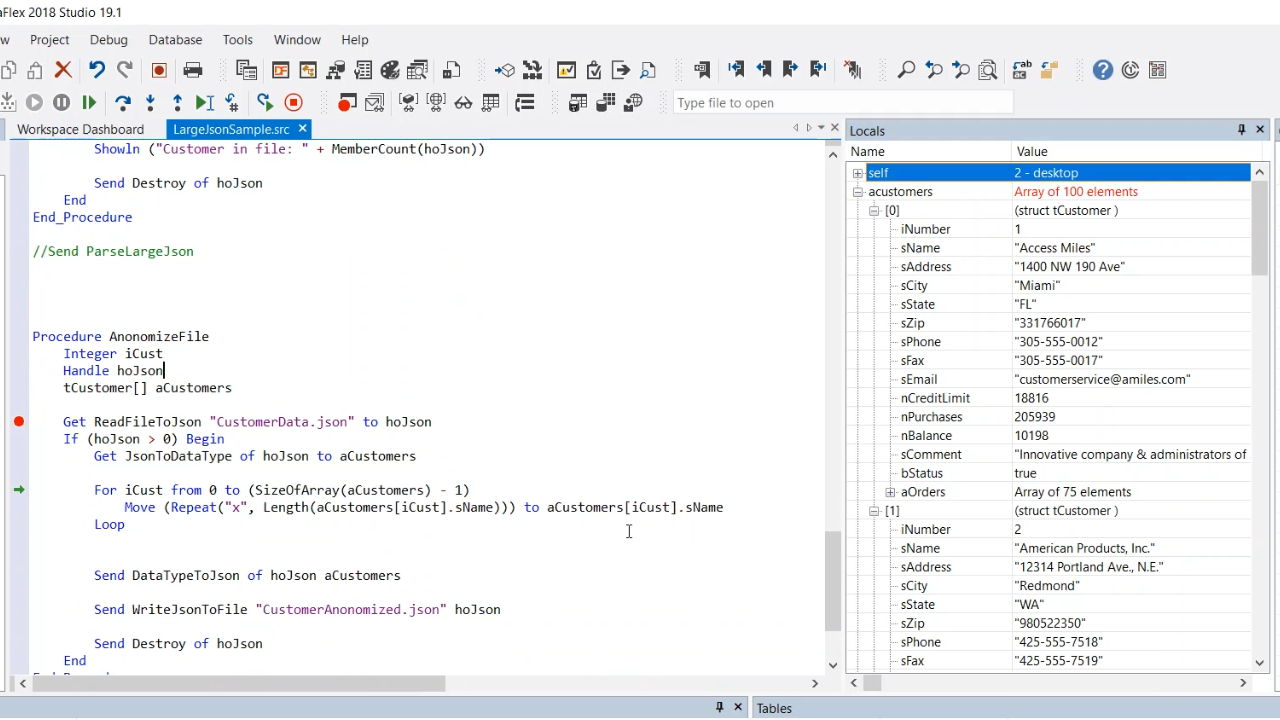
- The next sample procedure is called AnonomizeFile. The first step is to read in the file, which returns a JSON handle. Then JsonToDataType is called. Next, the JSON in memory is going to be converted into the tCustomer struct array. The array of customers shows that it has 100 elements (customers) in memory, and there is an array of orders for each customer.
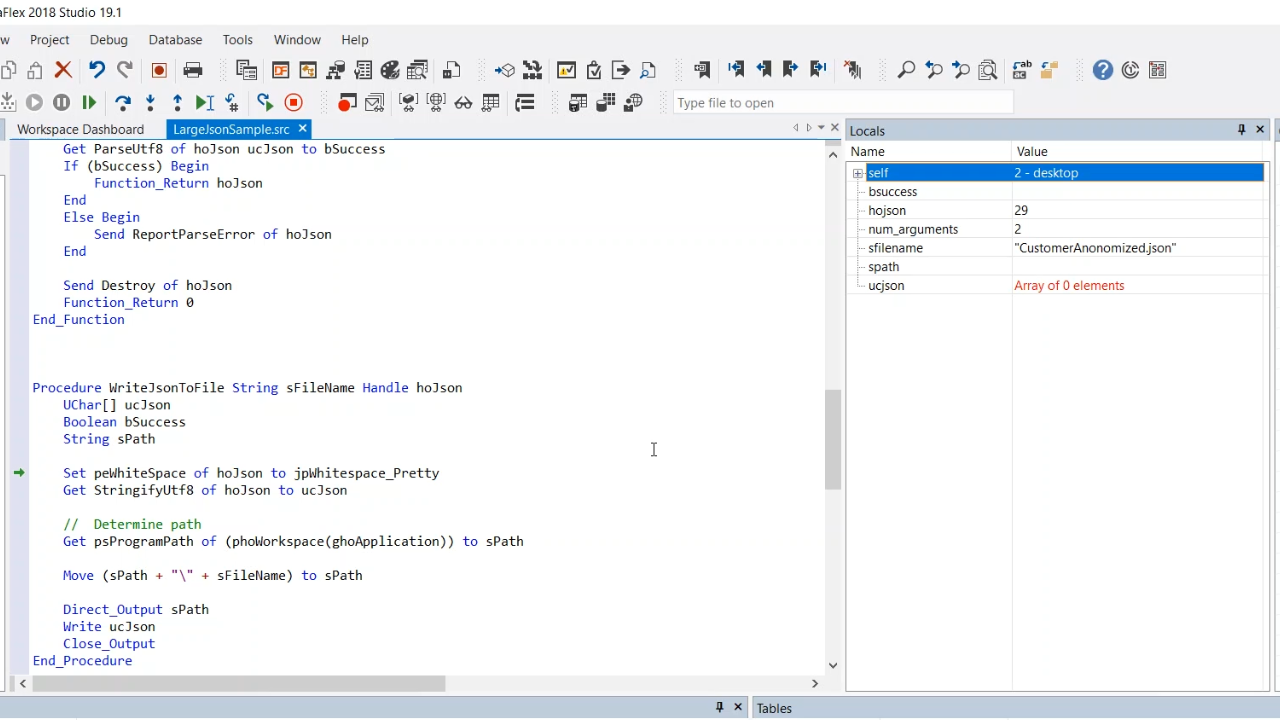
- Next the data will anonomized by replacing the customer name with xxxxxxxxxxx. All the data will be looped over to do so. The data is then converted back into JSON by calling DataTypeToJson (hoJson now contains the updated JSON), which basically throws away the existing JSON structure that the JSON handle holds. It generates the new JSON structure in memory that can be written out to a file with WriteJsonToFile that is being called with a parameter. Next, peWhiteSpace is set to jpWhtespace_pretty. StringifyUtf8 is called and will return a UChar array. This will all be outputted to a file using Direct_Output, Write ucJson and Close_Output.
- Looking at the programs file structure shows a new file was created called CustomerAnonomized.json.
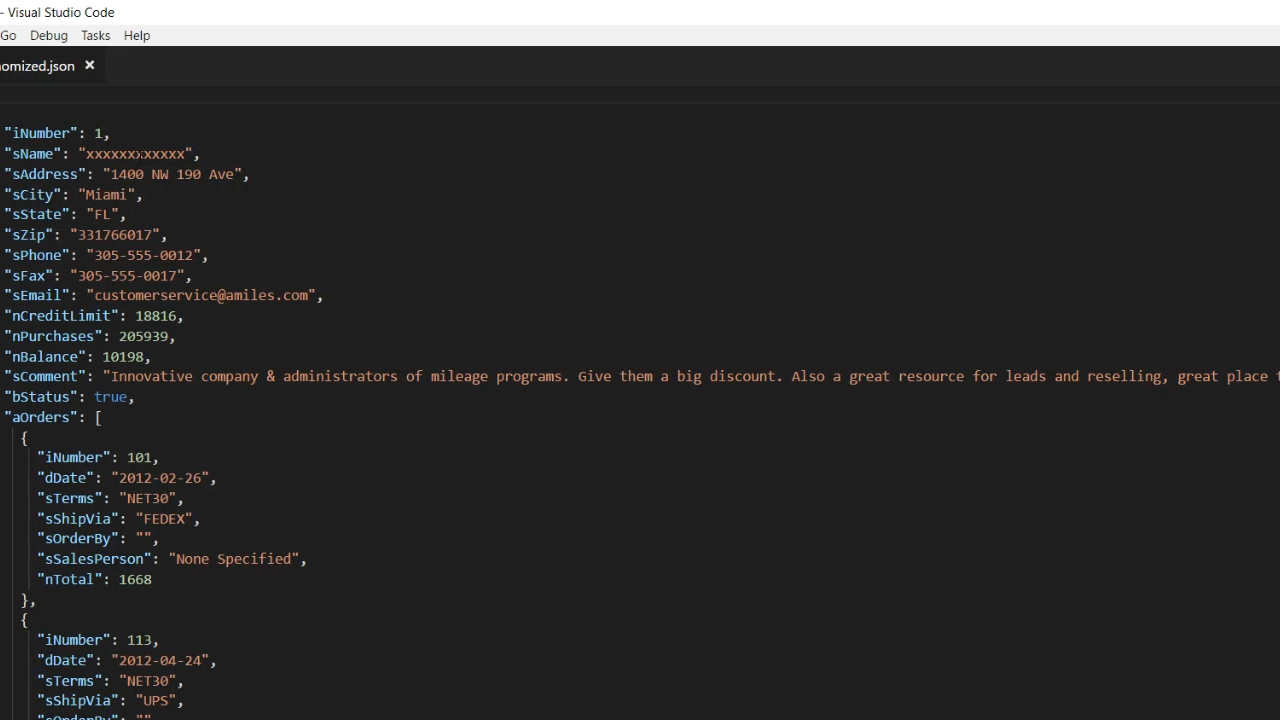
- Opening it shows that all of the customer names have been changed.