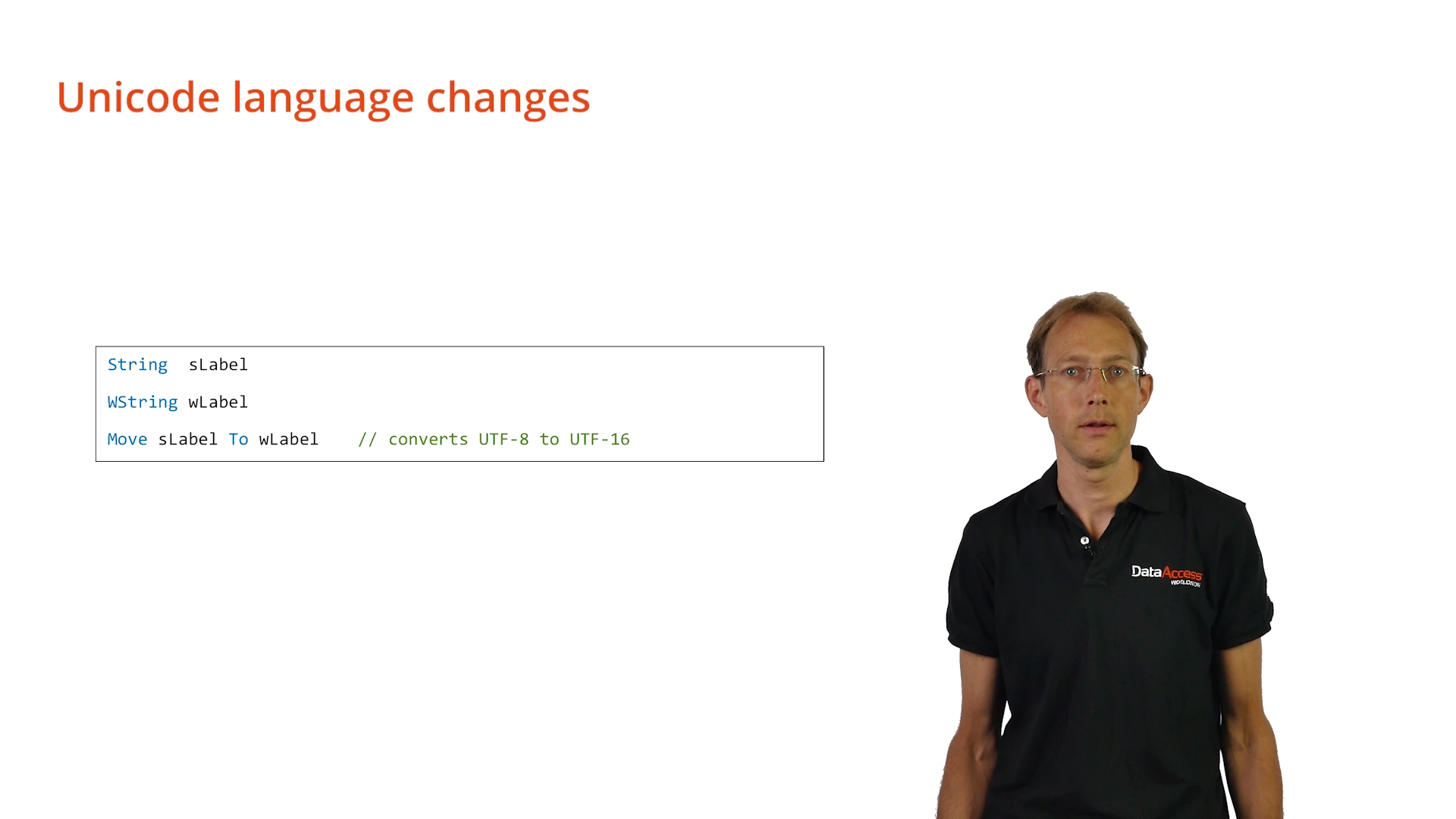
This lesson will discuss the language changes that have been introduced in DataFlex to assist with working with Unicode. A new native string datatype, the ‘WString,’ has been added. This is a UTF-16 string, which has been created to simplify communication with the Windows API, and other UTF-16 external APIs. ‘WString’ should not be used in other coding if it is not needed. Runtime functions work as ‘String,’ and ‘WString‘ needs to be converted to ‘String’ first, and then converted back afterwards. That would be inefficient. Simply working with ‘String’ is faster and more efficient.

Conversions can be made between ‘String’ and ‘WString,’ simply by using a ‘Move’ statement. The actual conversion between UTF-8 and UTF-16 is then done automatically by the runtime.
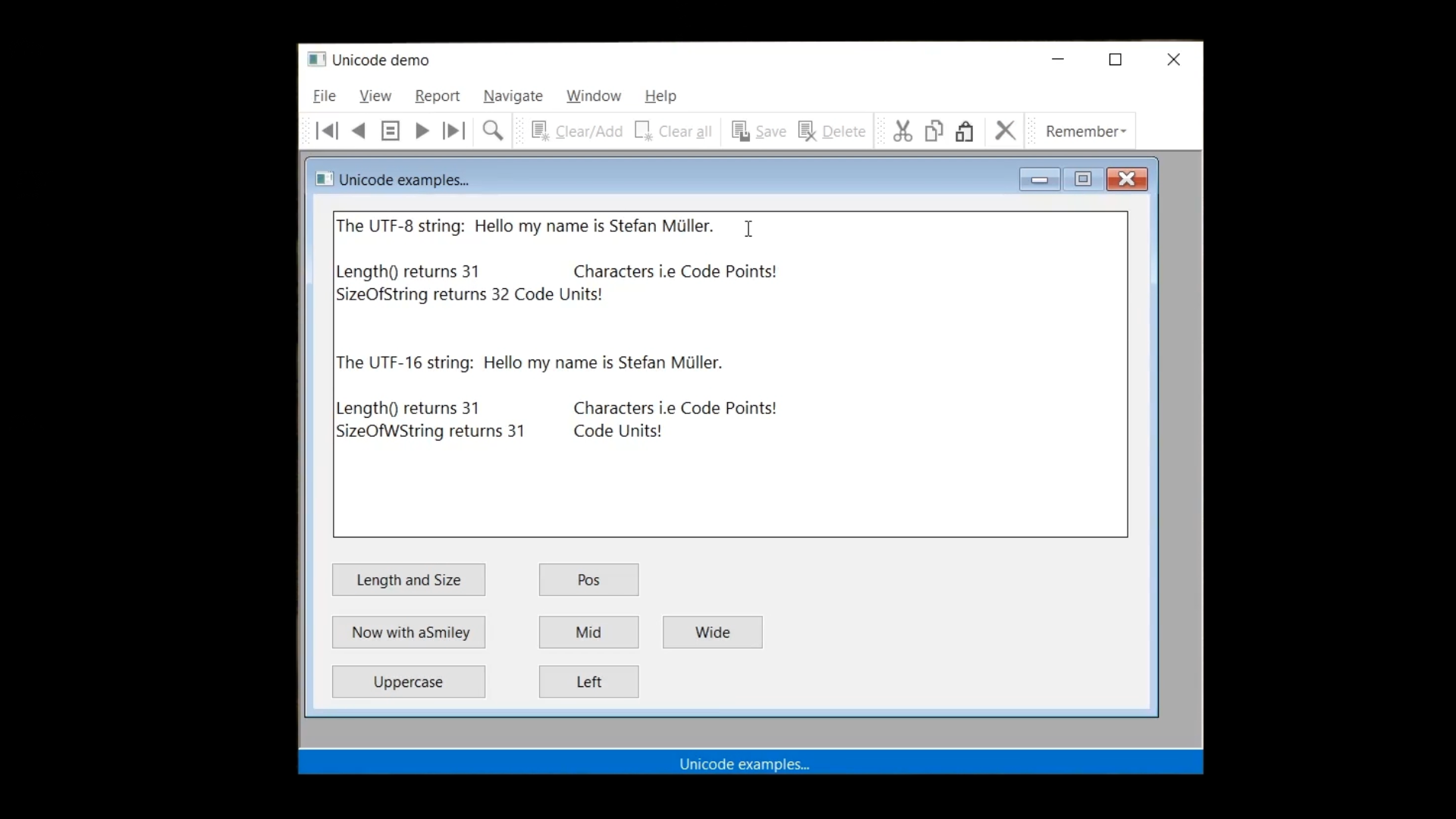
Before DataFlex 2021, the length of the string (the number of characters in the string) was always the same as the size of the string (the number of bytes). As explained in lesson 6, this is no longer the case. They can now be different.

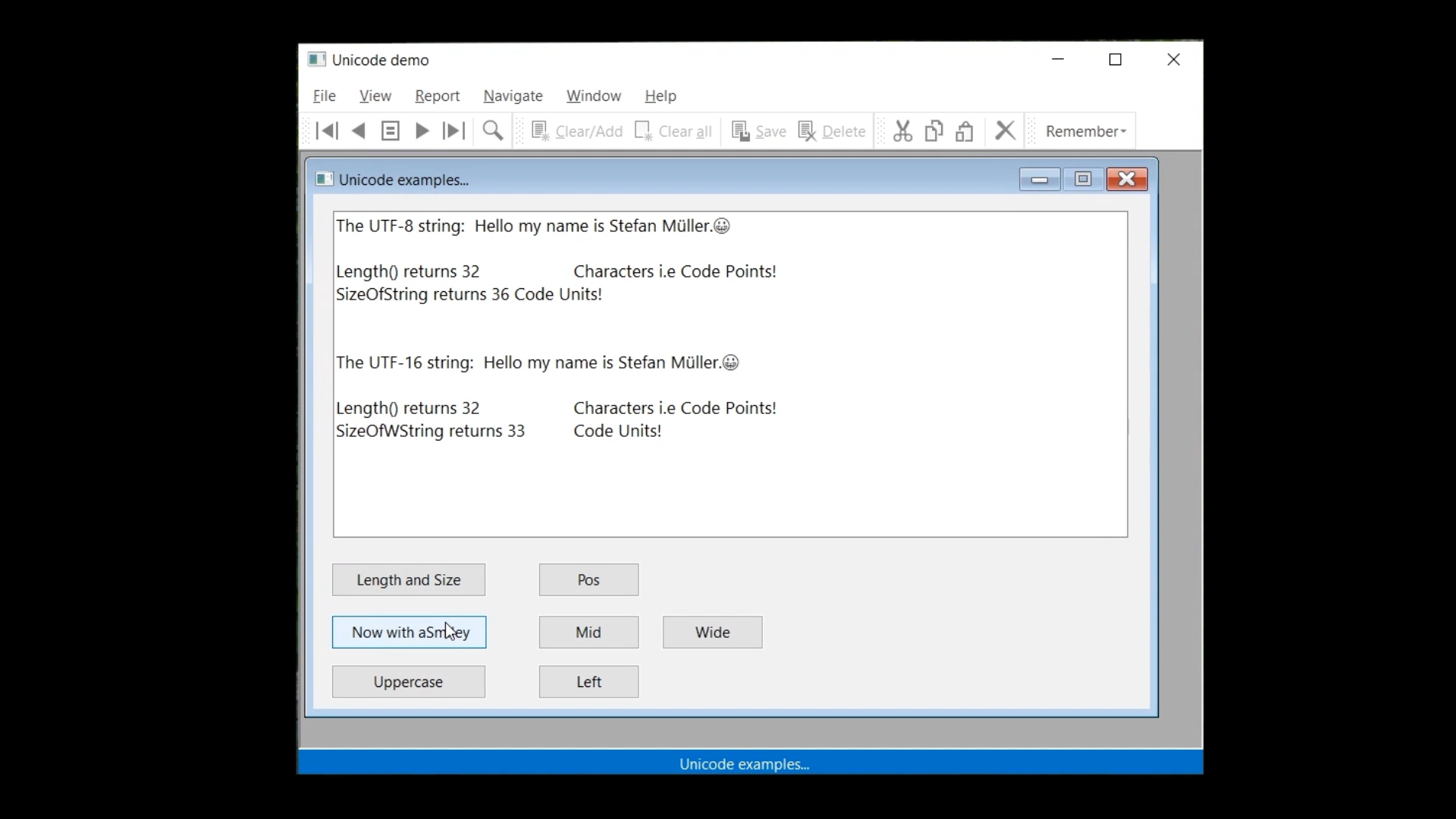
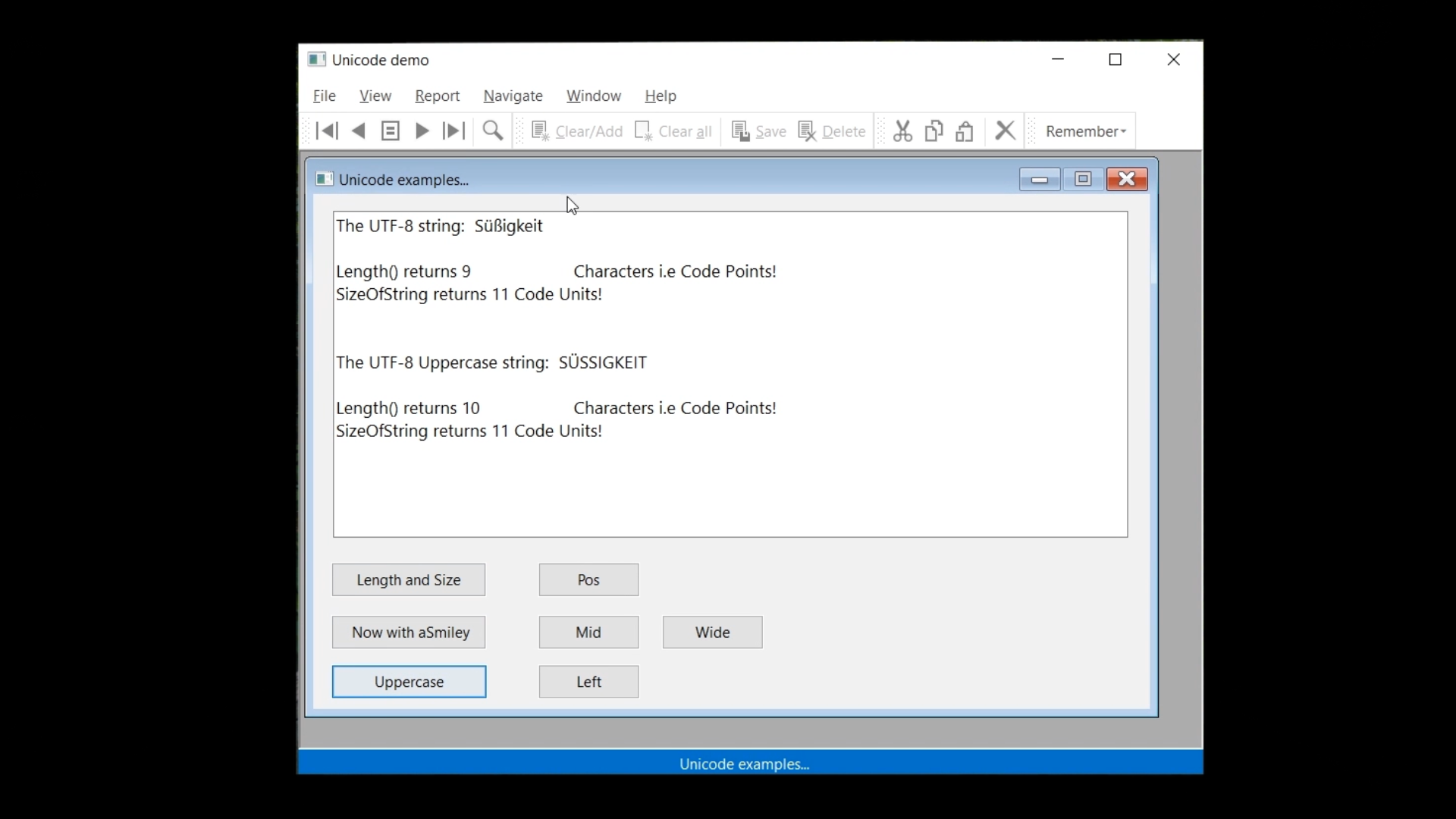
Characters can be different number of bytes. In Dataflex 2021, the ‘Length’ function still returns the number of characters of a string. ‘Length’ also works for ‘WString,’ but it should not be used anymore for getting the size of a string (the number of bytes). There is a new function for that, called ‘SizeOfString.’ It returns the number of bytes, which in UTF-8, is equal to the number of code units. A similar function exists for the ‘WString’ type, which is ‘SizeOfWString.’ This function will return the number of UTF-16 code units. So, the number of double bytes.
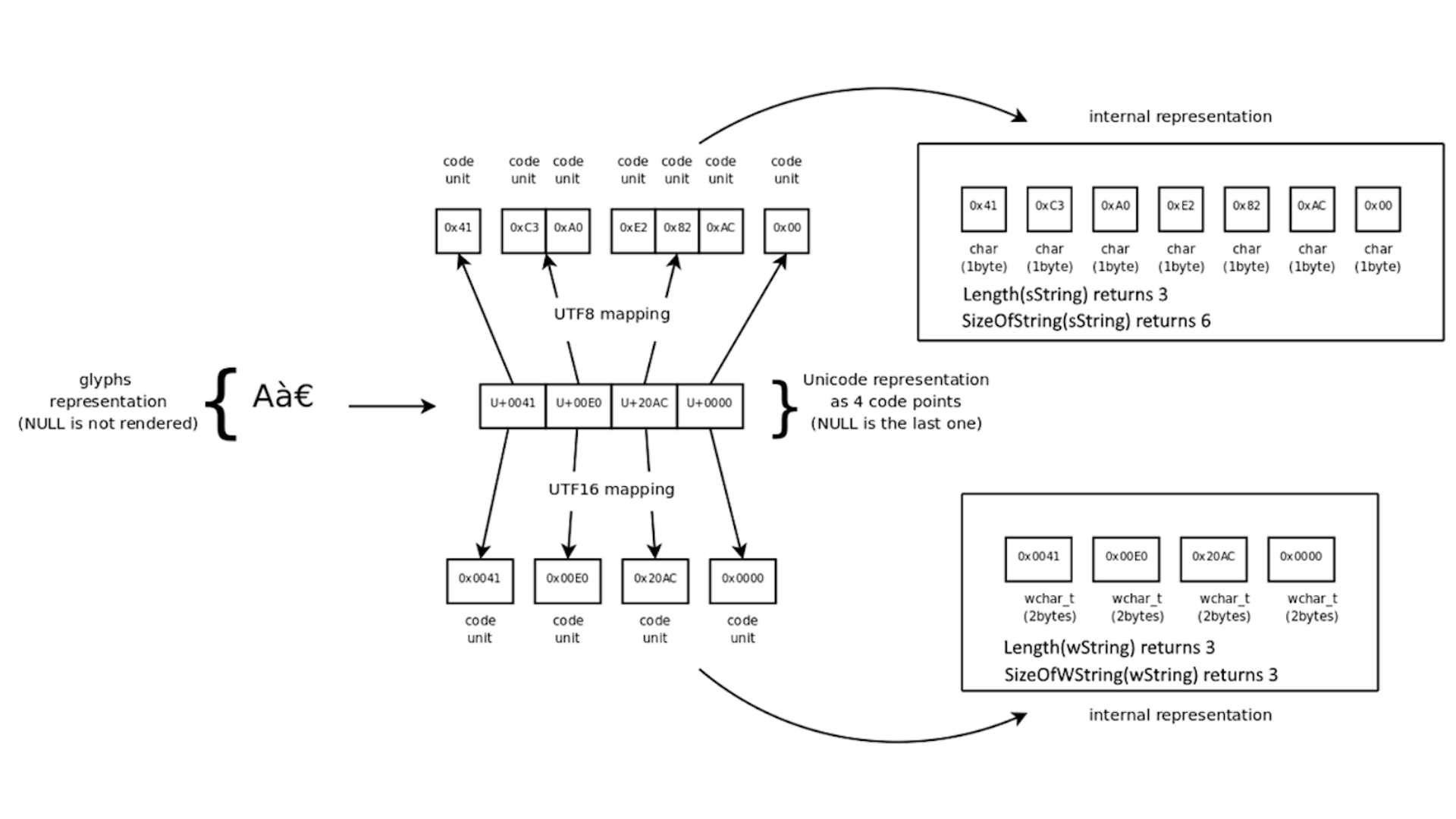
In this example, ‘SizeOfString’ returns the value 6, because the capital A is one byte, the accent a is two bytes and the euro sign is three bytes. In the last line, ‘SizeOfWString’ is performed on the same ‘String,’ but ‘SizeOfWString’ expects a ‘WString,’ so what happens is that first, in the runtime, ‘sLabel’ is converted to a ‘WString,’ and then ‘SizeOfWString’ is performed on that ‘WString.’ A value of 3, three code units, is returned. This is because in this instance, each character is one code unit. For a UTF-16 string, each code unit is two bytes, so the string size in memory is 6 bytes.

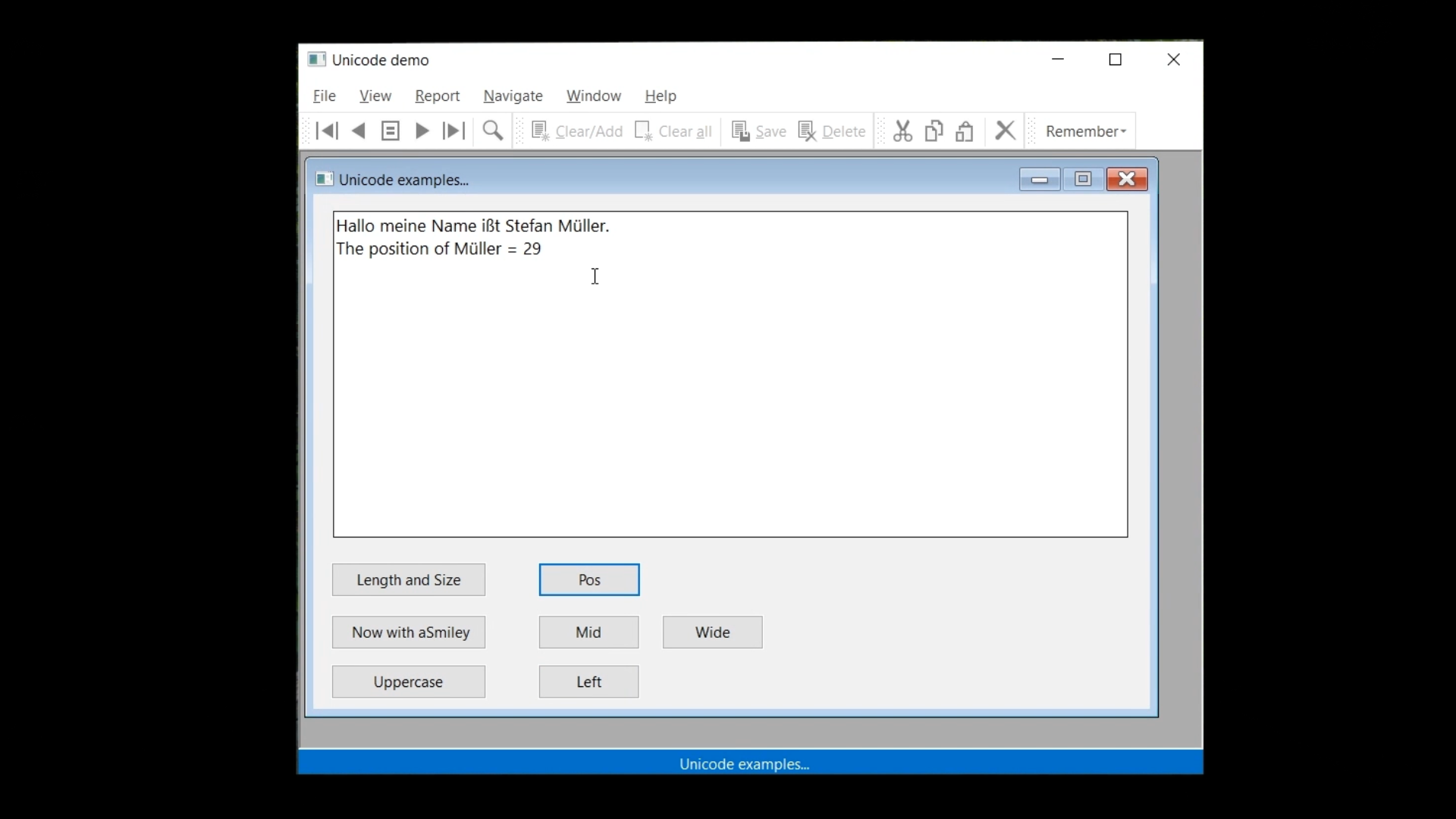
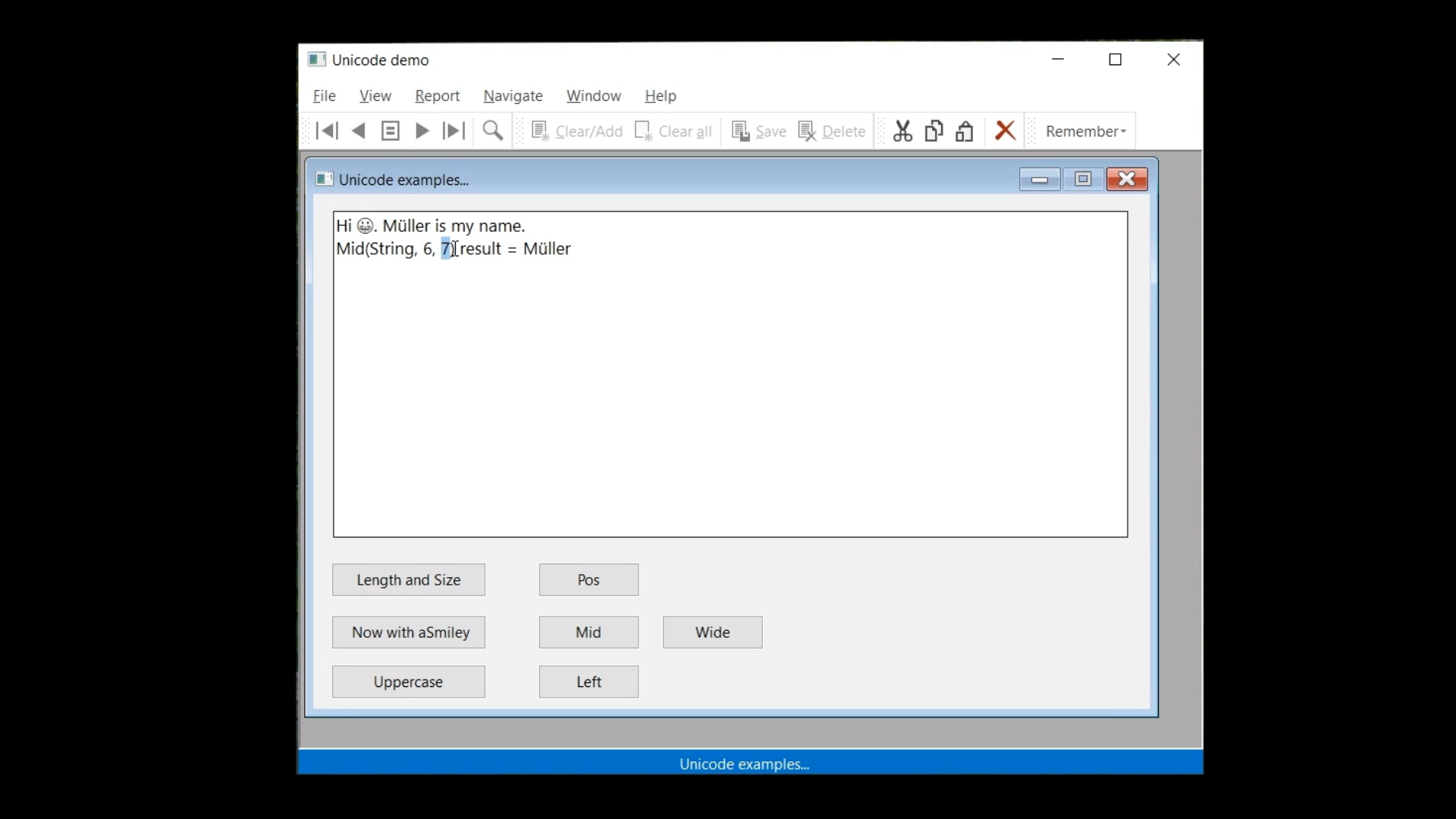
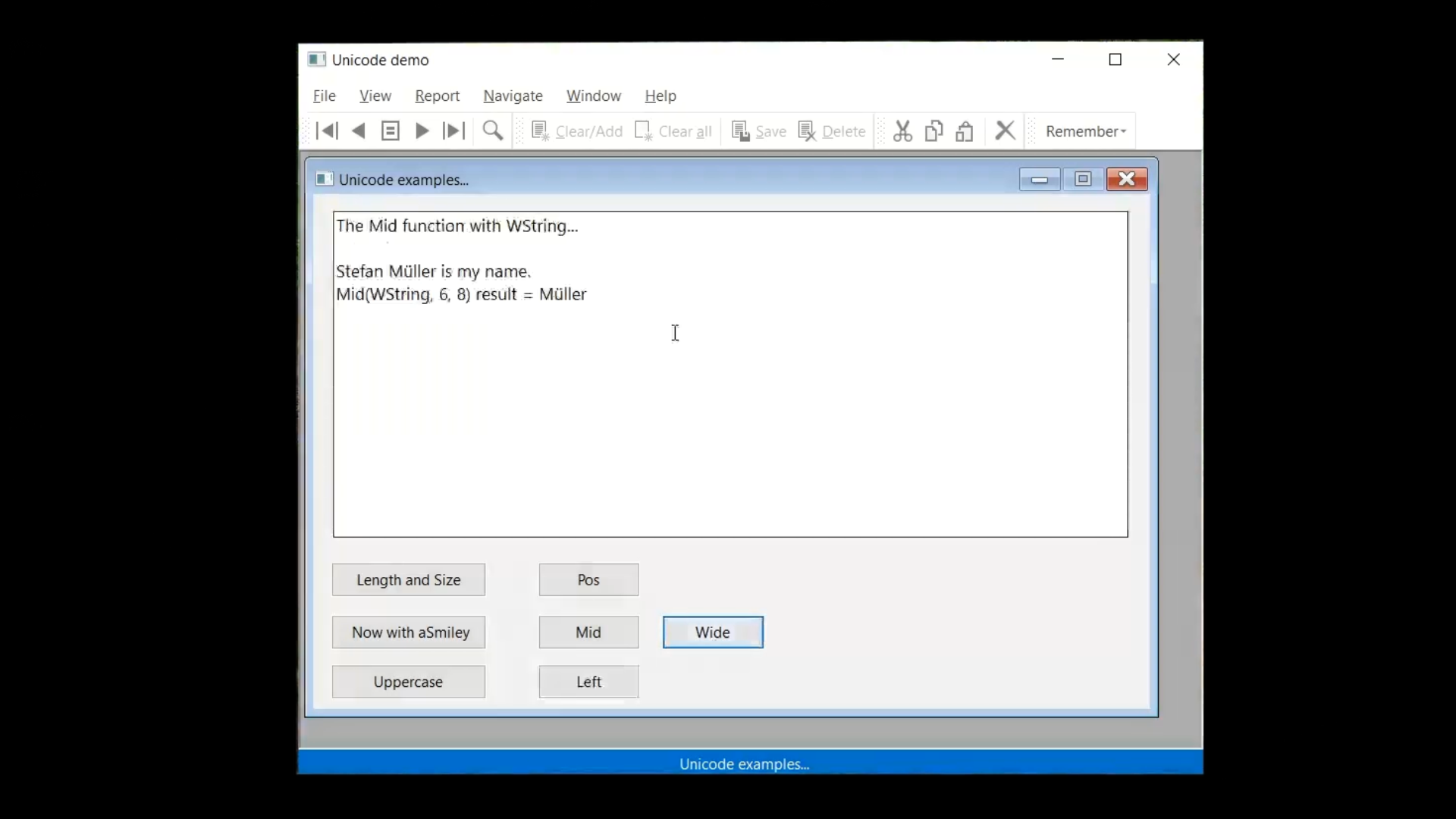
All other string functions work on the regular UTF-8 string, and they are character based. Such as the ‘Pos,’ ‘Left’ and ‘Mid’ functions, so they probably still work well in the code, unless the result is used as the number of bytes for memory operations or something else.