Now that Unicode has been explained, the next step is to look at how Unicode affects the DataFlex environment. DataFlex 2021 is fully Unicode, which means that all strings are Unicode, they are UTF-8. But if looking at the entire DataFlex 2021 environment, different encodings may be used in different parts.

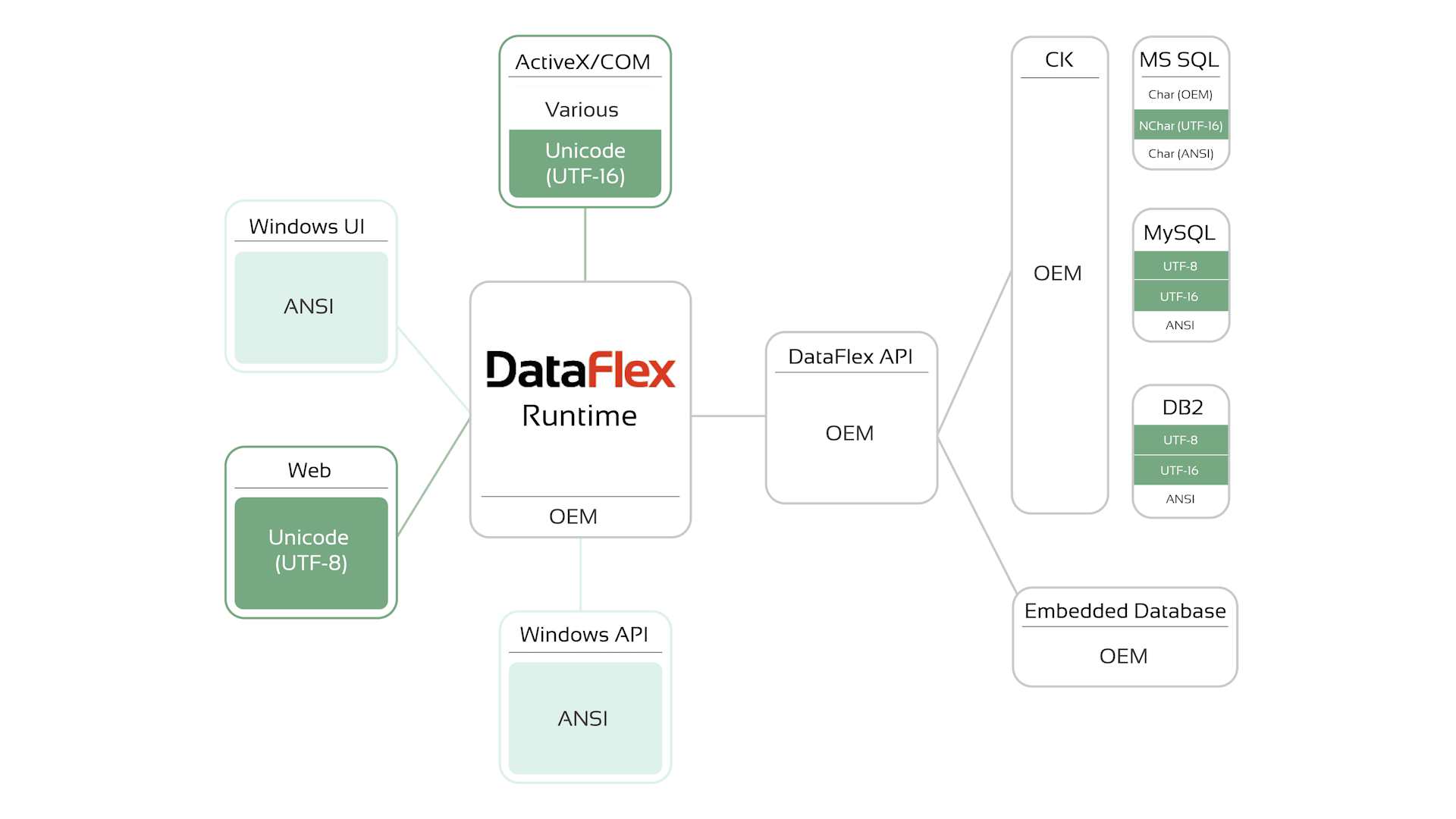
This is how it was prior to DataFlex 2021. DataFlex itself, the embedded database and the interface to other databases was OEM. The connectivity kits allowed any encoding in the database. The Windows API and UI are ANSI, which meant conversions between OEM and ANSI were needed. The WebApp Server was already using UTF-8 in prior versions.
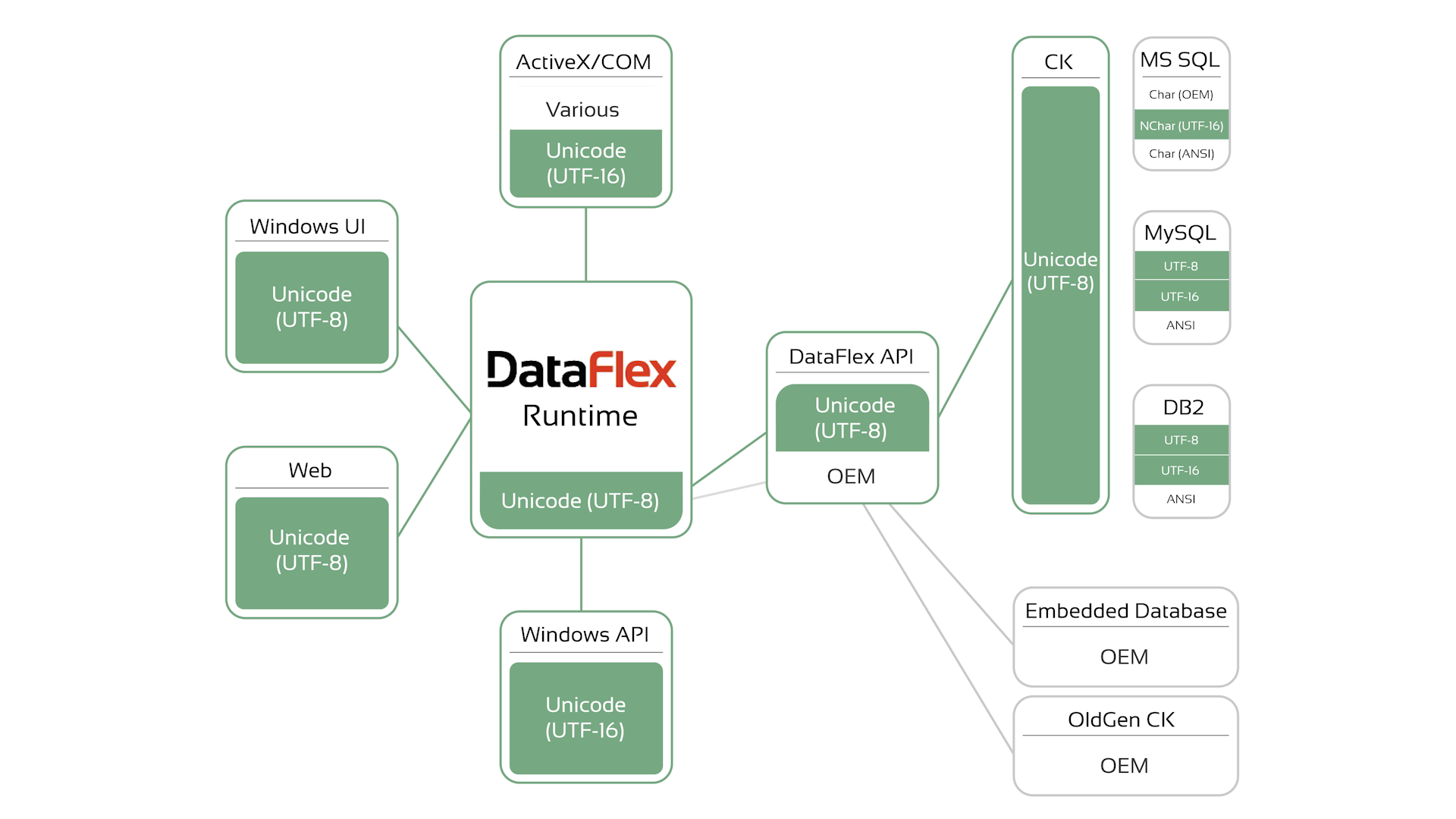
Much has changed with DataFlex 2021. The items indicated with dark green are Unicode. Most items are now UTF-8. The Embedded database, however, is still OEM. The DataFlex core API has a layer to automatically convert between UTF-8 and the OEM embedded database and older versions of the connectivity kits. The connectivity kits that come with DataFlex 2021 do the conversions between the UTF-8 DataFlex string and whatever type of string is used in the database, such as VarChar and NVarChar. String types can be set from the table editor in the Studio. Windows APIs are UTF-16. ANSI version can still be used, but it is best to start using the UTF-16 versions, and the standard packages do that. Other external APIs can use any encoding.
The DataFlex language string is no longer OEM; it has become UTF-8. If the use of an OEM string is desired, which is unlikely, then the standard DataFlex string can no longer be used for that. There are a couple of special things about the DataFlex UTF-8 string type that are important to know.
First, if hashed strings are used, for example for passwords, beware that if there are characters outside the ASCII set, a hashed OEM string from previous DataFlex versions can be different from a hashed UTF-8 string. Second, in the past, DataFlex strings were sometimes used to store binary data. This technique is not recommended. Instead, use UChar arrays.

The string functions and the debugger now try to interpret the strings as UTF-8 data. Binary data, in a lot of cases, is not valid UTF-8. String functions no longer translate their parameters directly to memory offsets. Now they interpret them as character offsets where they will analyze the string to convert them to memory positions. This will go wrong when the data are not valid UTF-8 strings. An added advantage of using UChar arrays is that the Max_Argument_Size does not apply to them.

As mentioned in lesson 4, there are several essential code changes that must be made because the DataFlex string has become UTF-8. An example is converting TYPE structures to Structs and removing or changing ToOem and ToAnsi calls. If not already done, please review lesson 4. In the source code, Unicode characters in string literals and comments can be used, but not in names of object, functions, and variables. As shown in lesson 2, the Studio editor saves sources as UTF-8.

What results when trying to store Unicode characters in the embedded database