



Part 1 of the Migrating to DataFlex 2021 course discussed how to migrate applications to DataFlex 2021, and what was needed to make them run well. It did not discuss making applications fully Unicode, however. Part 2 of the course will go into the details of supporting Unicode in DataFlex applications. To start, Unicode must first be introduced and explained.
In short, Unicode is an information technology standard for the consistent encoding, representation, and handling of text, expressed in most, or perhaps all, of the world's writing systems. Unicode offers a solution to the problems involved with using multiple character encoding standards, or code pages. It provides a unique number for every character, and it will be clear to any computer program what the character should be. As a result, Unicode allows mixing of any language in an application. It also allows the usage of emoticons and pictogram-like characters. Unicode is not simple. In fact, there is not a single Unicode thing. There is Unicode, but there are many different encodings.

Some background is needed to explain this. The ASCII character set was introduced in the 1960’s. This 7-bit set, with 128 characters, contains the numbers, the lower- and upper-case letters and some special and control characters. In the 1980’s, the 8th byte was used as a parity byte, to define another 128 characters. This extra set can be changed by using a different code page.
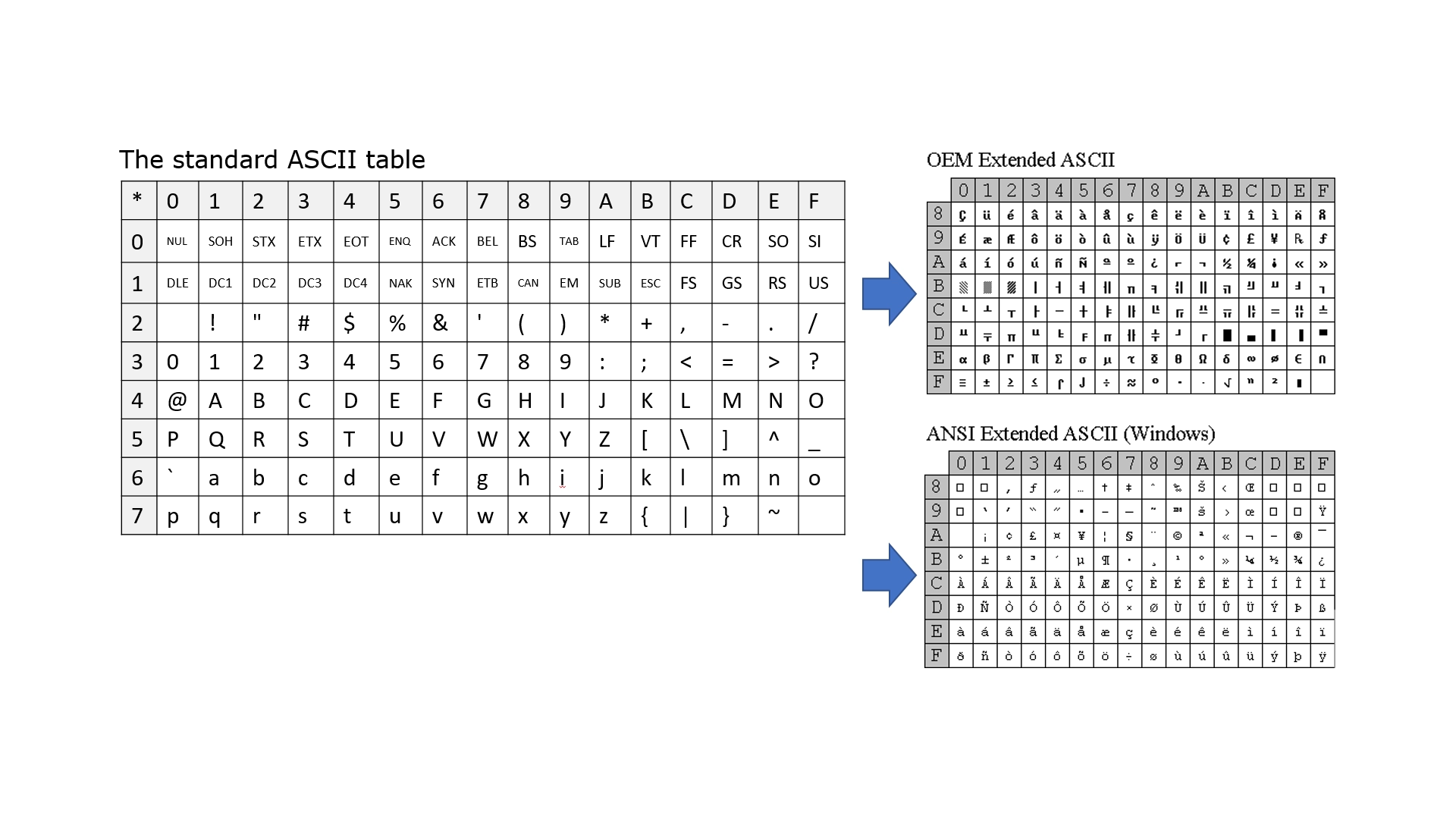
There are many code pages. There are multiple OEM code pages for different languages that were introduced for DOS. There are also multiple ANSI code pages, which are for Microsoft Windows. In general, ANSI refers to the Windows-1252 code page on Western and U.S. systems. It is important to note that OEM and ANSI code pages are different. Only one code page can be used at a time, so for example, Greek characters cannot be stored while working with the western code page 850. All these character encodings are one byte per character, so they cannot hold more than 256 characters. To allow for more characters to be used in a single application, more bytes must be used, and that is what Unicode is about.

There are different Unicode encodings, most notably UCS-2, UTF-8, UTF-16 and UTF-32.






UTF-8 and UTF-16 are the encodings to focus on because DataFlex strings are UTF-8, and Windows strings are UTF-16. Conversions between them can be done and are needed to make DataFlex applications communicate with Windows API. For a better understanding of what this involves, it is important to know what “code points” and “code units” are. In short, a code point reflects a character. And a code unit is the size of the building units. This is one byte in UTF-8 and two bytes in UTF-16.

For example...
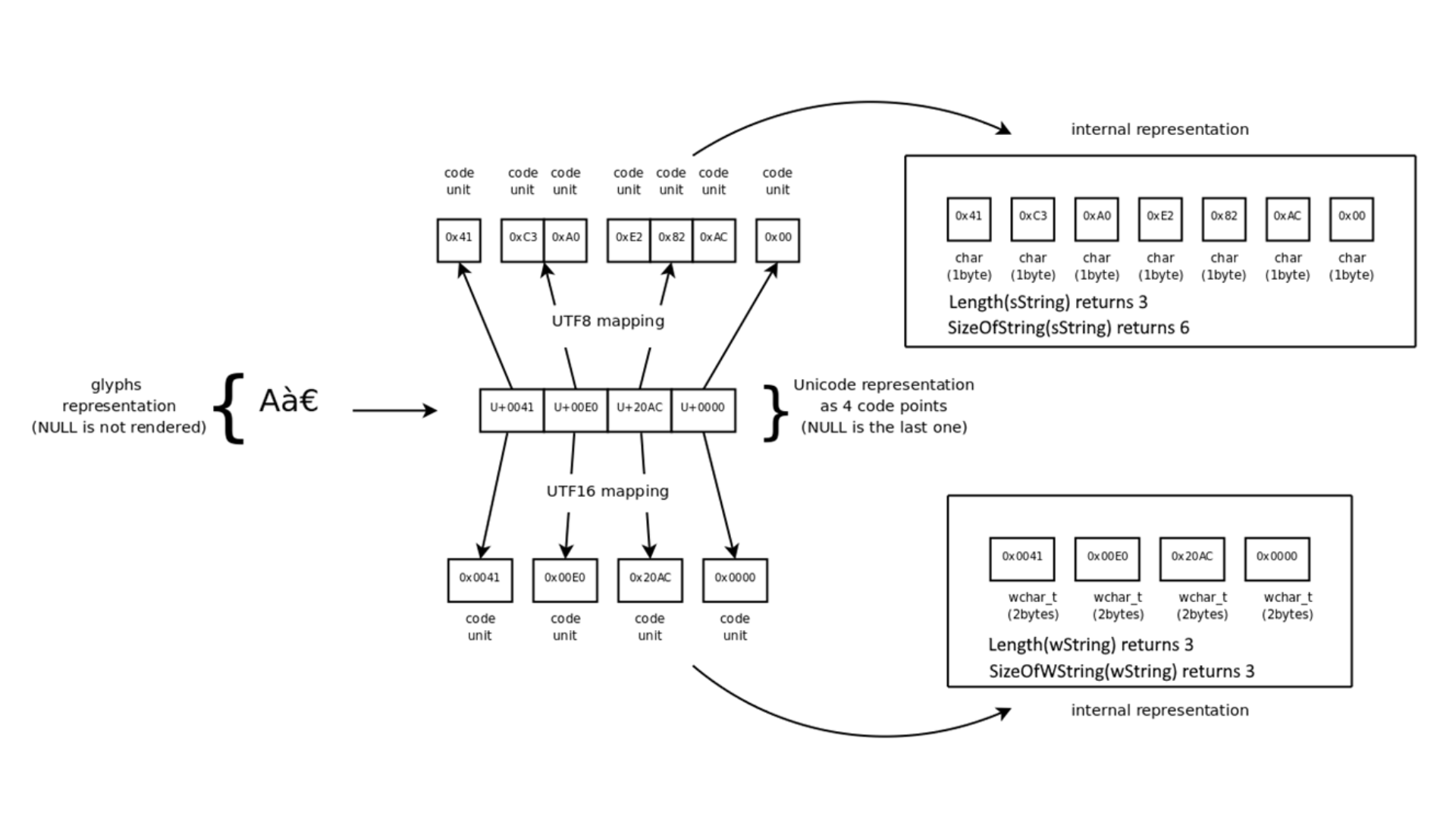
Here a Unicode string of three characters is shown: Aà€. These are four code points because a termination NULL is added. Now, depending on the encoding, this is a different number of bytes and a different number of code units. In UTF8, the first character is one byte, and in UTF-8 each byte is a code unit. The second character is two bytes, and, therefore, two code units. The third character is three code units. The terminating null is one byte. Then there are seven code units. The size of the string, in DataFlex, does not include the terminating null, so the string size is six bytes.
Now look at UTF-16. The first character is one code unit. In UTF-16 each code unit is two bytes, so this character is two bytes. The other two characters also are one code unit each. The total size of the string is 6 bytes, which is coincidentally equal to that of the UTF-8 string. This is often not the case.
