



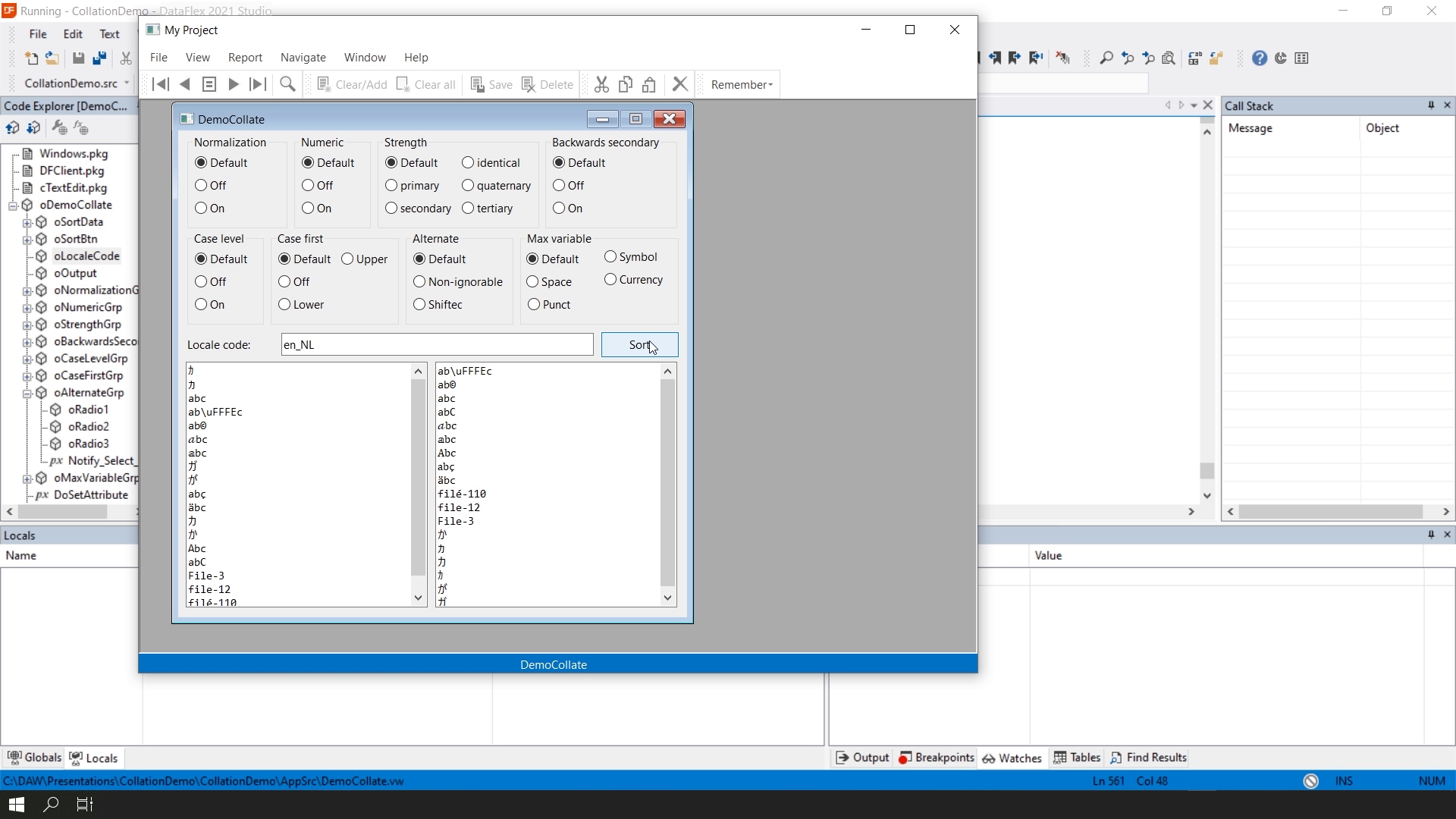
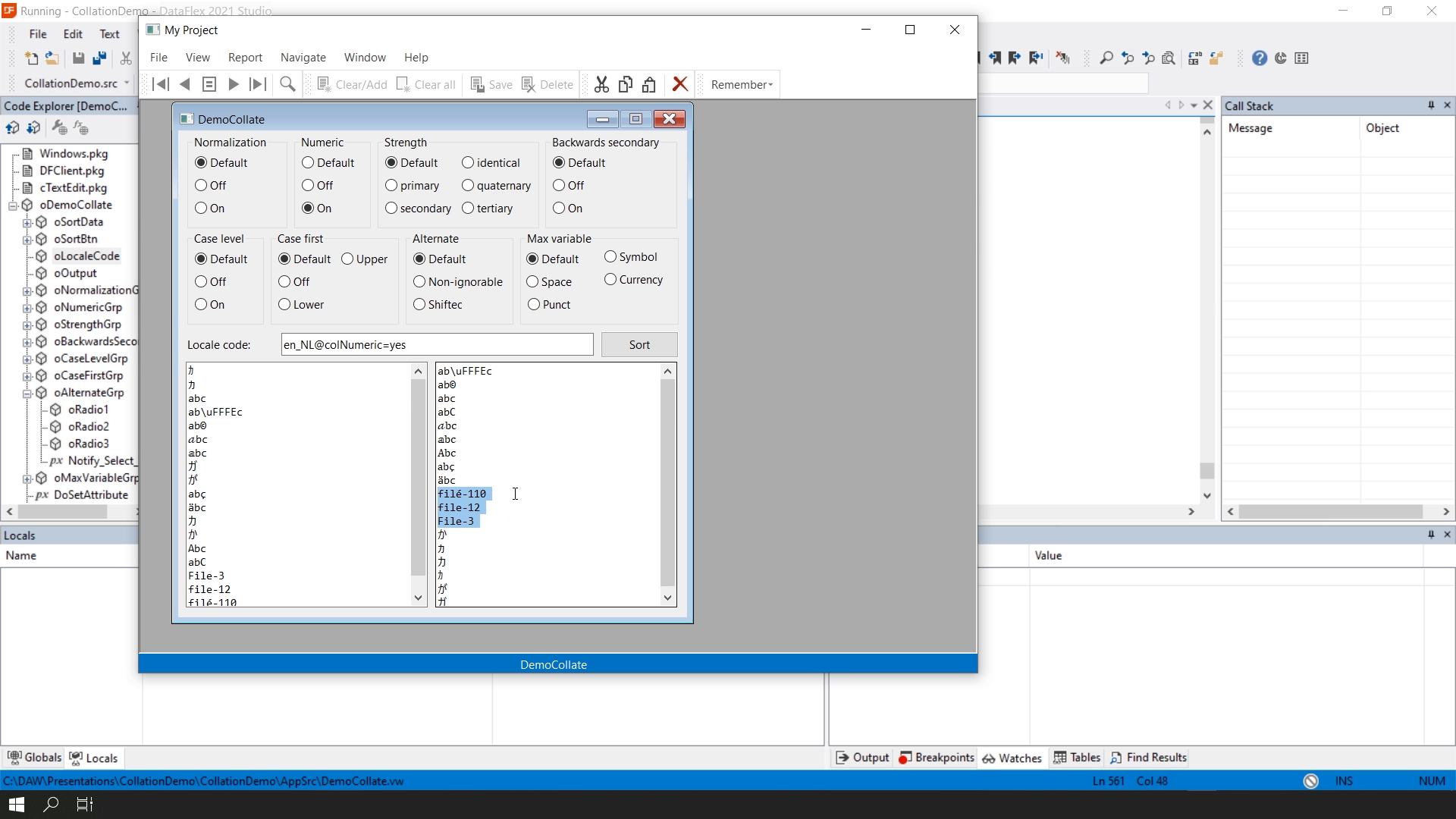
This lesson we will look at sorting and comparing string data from the database, otherwise known as collation. Character data is sorted and compared using rules that define the correct character sequence, with options for specifying case-sensitivity, accent marks, etcetera.String comparisons with Unicode are much more complicated than with OEM or ANSI. DataFlex 2021 uses the ICU Library for comparing strings according to the Unicode standards. ICU is a cross-platform Unicode based globalization library. Multiple collations are supported and can be configured via the new DF_LOCALE_CODE string attribute. This global attribute defaults to the language of the operating system and can be changed at runtime. This website for the available locale codes: http://userguide.icu-project.org/collation/customization
Note that when using the embedded database, the indexes will be built up according to the old collating system configured via DF_Collate.cfg for backwards compatibility.

This is the end of part 2 of this course on Migrating to DataFlex 2021. In this part you have learned what Unicode is and how you can convert your software to support Unicode. In the next part, I will go into detail about 64-bit. The next part will be online later this year!
